无觅网络:1+1大于2

自从2月底推出无觅网的第一版到现在已接近10个月了,许久没更新博客,今日借推出无觅网络这产品给用户交代一下无觅想走的路。
无觅的理念是想让互联网变得更聪明、更个性化,而去实现这理念的基础是 “1 + 1>2″。
1 + 1 为何大于2?
笔者读研的时候第一次接触到推荐系统是来自导师介绍的一篇文章叫“Collaborative Filtering…”,中文翻译成协同过滤。当时的第一反应是诧异,推荐是多给你些你感兴趣的信息,怎么成了过滤了?后来理解到推荐你感兴趣的信息其实就是过滤掉你不感兴趣的信息,只是角度不一样而已。但真正留在笔者脑海里的是协同过滤这背后的意义,很多东西单独存在的时候并没多大用途,合并起来却能产生新的价值,这么简单的道理原来也能应用在算法里。协同过滤法的原理非常简单,就是基于人有相似、物有相近,要推荐书给你,只需找到与你口味相近的人,把他们喜欢看的书而你还没看过的推荐给你,很大可能性你也会喜欢(因为你们口味相近)。两个兴趣相似的读者,各自点了一篇他们感兴趣的文章,这两个点击单独存在可能都已没有用,但合并起来却能给对方推荐。单个神经元(neuron)起不了什么作用,但无数个神经元有意义地连接在一起就成了我们的大脑了。日常生活中类似的例子比比皆是,这看似简单的逻辑成了无觅的灵魂:公司名字为“二木”,推荐算法采用了协同过滤,及今日要推出的基于网站互连的无觅网络。
从相关文章插件说起
无觅几个月前研发了一款相关文章插件,深受站长的喜爱,国内很多知名的博客都在使用。相关文章插件至今存在已非常多年了,随便在wordpress上搜一下也有几百个,无觅为何要再重新做一次呢?最根本的原因是插件有其限制性,创新的空间很小(这里的插件指的是一般附属在博客框架如wordpress、zblog等等的插件)。
常见的做法
相关文章插件最常见的做法就是依赖文章的标签(Tag),标签一样意味着两篇文章在某程度上的相关性,越多一样的标签就越相关。这很容易理解,算法也很简单,一般对网站服务器不会造成太大的压力。基于类似的想法,有些插件也考虑了文章类别、内容、时间等等,但这些都有一个相同的致命点。
弊端
一般插件的算法处理都是在插件端完成,这意味着插件运行的速度得非常快,否则便会影响网页的加载速度,这也是大部分站长不喜欢装太多插件的主要原因,以免影响速度。这么一来,相关文章的创新就给大大的局限了。这里指出一些相关文章可以改善的地方,但因为插件环境受限而难以实现。
1. 引入行为数据将有助读者发现更多好文章。行为数据指的是那些你经常在淘宝或亚马逊看到的“买了这个也买了那个,或看了这个也看那个“的功能。推荐系统里最经典的协同过滤法因需要处理时间比较长,一般插件难以实现。
2. 文章的标签权重可能不一样,一篇文章有多个标签,但可能里面的某个标签才真正代表这篇文章的主题,如能辨别出不同标签的权重将有助找到更相关的文章。
3. 处理图片、视频等繁重的工作通常耗时较久,难以直接在插件端完成。
4. 或许以后的相关文章不再局限于相关文章了,而是推荐,是用户感兴趣的但未必跟正在看的相关。又或许相关文章不再局限于站内的,而可以是互联网上的任何一篇相关的文章。
云端相关文章插件
或许有人会认为这种改善可以带来的价值很有限,可能不值得去做。但当初Google开始做搜索的时候,搜索行业也不被看好。为了可以脱离一般插件的受限,无觅采取了云计算的模式:
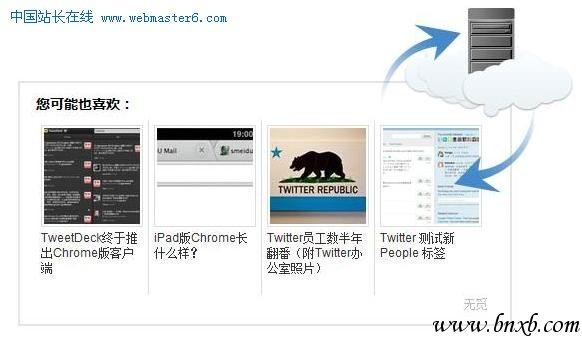
插件端的主要工作就是发个请求给无觅服务器,然后返回相关文章。这种做法一来不会对网站主的服务器造成任何压力,二来给了无觅很大的空间去创新。无觅可以进行任何复杂的算法去计算相关度,做需时较久的图像视频处理,只需把结果缓存起来就行。国外也有几家采取类似的模式,但对于中文网站文章的相关度总是强差人意。因为有了创新的空间,无觅相关文章插件现在给网站多带去平均10%-20%的页面访问量。
- 最新评论